
AlphaGeometry2 vs Gemini 2.5 Pro: Neuro-Symbolic Creativity and the Power of the Prompt
What a neuro-symbolic system and a large language model teach us about creativity, rigor, and the evolving architecture of intelligence

toString() is hands-on AI + architecture for busy engineers. If you want runnable blueprints subscribe—it helps me keep shipping these.
Hey Hey! For the past two weeks, I've been fascinated by and obsessed with researching the fantastic results that Google DeepMind achieved at the Math Olympiad, where they won two gold medals with two different systems. I believe these two systems are a good proxy for how AI architecture will evolve. Okay, let's start by explaining "what happened" and which systems were involved
Google DeepMind, through
AlphaGeometry2, successfully surpassed the performance of an average gold medalist in solving Olympiad geometry problems, achieving an 84% solve rate on all International Mathematical Olympiad (IMO). This neuro-symbolic system, an upgrade to the original AlphaGeometry, leveraged an expanded domain language, a faster symbolic engine, a more powerful Gemini-based language model, and a novel search algorithm.
Google's Gemini 2.5 Pro model, equipped with a sophisticated self-verification pipeline and careful prompt design, tackled the full International Mathematical Olympiad 2025, solving an astonishing 5 out of the 6 problems correctly and achieving a gold-medal standard This showcased the immense potential of powerful Large Language Models (LLMs) when guided by optimal strategies for complex reasoning tasks.
Ok, now let's see how these systems have been designed and what are the differences.
AlphaGeometry2 (AG2) is a neuro-symbolic system specifically engineered to tackle Euclidean geometry problems at the Olympiad level. It's essentially a brilliant system that combines two main components: the Neural part that provides the creative thinking (like an LLM) and the Symbolic one that is a system that is built to read, write, and reason following mathematical symbols and logic.
The neural part of AlphaGeometry2 is a language model based on the Gemini architecture. This model is trained from scratch with a larger and diverse dataset consisting of millions of synthetically generated geometry theorems and their proofs. Its primary role is to guide a symbolic deduction engine by proposing auxiliary constructions. The language model acts as an agent that generates these constructions that are like "proposed ideas and solutions approach". Then, the symbolic engine attempts to deduce the proof that you can see or a very sophisticated math engine that tests the proposed idea of the agent.
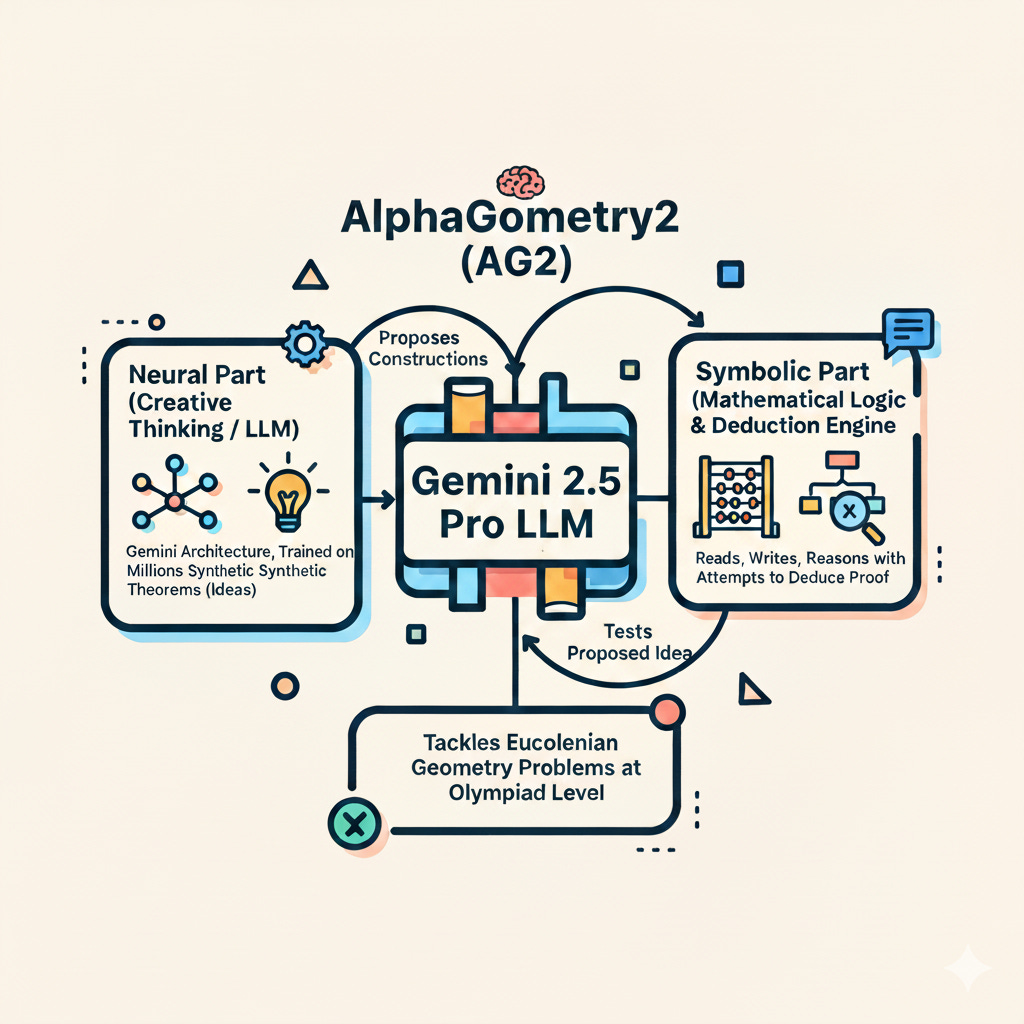
These two components are integrated through a search algorithm called Shared Knowledge Ensemble of Search Trees (SKEST). In this system, multiple differently configured beam searches run in parallel, and critically, they can share facts they've proven through a knowledge-sharing mechanism.This dynamic interaction allows the neural model to propose creative idea on how to solve the problem, and the symbolic engine to rigorously verify deductions, iteratively working towards a solution.
In contrast, Google's Gemini 2.5 Pro model achieved its gold-medal standard by leveraging the immense power of a large language model through a sophisticated self-verification pipeline and careful prompt design. While AlphaGeometry2 is a specialized neuro-symbolic system for geometry, Gemini 2.5 Pro is a general-purpose LLM tackling the *full range* of International Mathematical Olympiad problems (algebra, number theory, combinatorics, and geometry).
As described here, we don't have a combination of different tools but a single large one, the Gemini 2.5 Pro LLM, which is instructed to act as different personas. The self-verification pipeline of Gemini 2.5 Pro works as an iterative loop:

1. Initial solution generation using a prompt designed to emphasize mathematical rigor and honesty about completeness
2. Self-improvement, where the model is prompted to review and enhance its own work. This step effectively provides an *additional "thinking budget"* as the model often consumes its initial token limit on complex problems.
3. Verification by a "verifier" agent (another LLM instance) that meticulously reviews the solution step-by-step, classifying issues into "critical errors" or "justification gaps" and generating a bug report
4. Correction or improvement of the solution based on the bug report.
The prompt design instructs the model to adhere to strict logical soundness, explain every step, avoid guessing, and present all mathematical expressions in TeX format. This iterative refinement process is essential for overcoming limitations of single-pass generation, such as finite reasoning budgets and initial errors, thereby extracting rigorous and trustworthy mathematical arguments from the powerful LLM.
So what this architectures are telling us about the future of AI, my main takeaway is that language models are becoming real orchestrators of tools. They're able to come up with ideas, suggest approaches, and even choose the best tool that can execute the proposed task, so I expect an even bigger shift of this way of using LMs.
Think about a few examples:
Scientific discovery: instead of a single model trying to “solve” biology, an orchestrator LLM could decide when to query a protein-folding engine, when to launch a molecular dynamics simulation, and when to invoke a symbolic theorem prover to test a hypothesis. The LLM doesn’t do the heavy lifting — it coordinates the workflow.
Software engineering: we already see LLMs writing code, but imagine a system where the model knows when to spin up a static analyzer, when to run security scans, when to query documentation embeddings, and when to delegate part of the task to a specialized code-generation model. The LLM acts as the “tech lead” orchestrating the whole toolchain.
On the other side, looking at Gemini 2.5 Pro’s success, I can’t help but be impressed by the power of the prompt. And this is coming from someone who (wrongly) always dismissed prompting as something annoying or superficial. What DeepMind achieved shows that prompts are not just a hack — they are a way to shape how a model reasonate, and it's really a form of engineering building a reasoning logical model to instruct the LLM
The takeaway for me is that even as models get larger and more capable, the interface — the way we instruct them is critical. Prompts act like a cognitive scaffold: they can enforce rigor, slow the model down, and guide it to check itself. In the future, I see prompts evolving into something closer to protocols or contracts between humans and models: highly structured instructions that guarantee a certain style of reasoning, self-verification, or tool use.
So while size matters, the Gemini case tells us that the future won’t just be about “bigger models,” but about better ways of steering them — where prompts become the control layer that unlocks reliability, consistency, and trust.