
Legacy AI #1 – E-commerce Recommendation Engines
The system behind “You may also like”

Once a month, I unpack an AI system that already works in production: how it’s built, why it scales, and what to copy. Each issue ships with clear patterns, diagrams, and an operator’s checklist you can use on Monday. We kicked off with e-commerce recommendations; next up: fraud detection—signals, architecture, and guardrails under 100 ms.
Subscribe to get the monthly deep dive. Paid readers also unlock industry use cases, printable infographic and the “do-this-now” toolkit.
Most people talk about “new” AI. But a lot of the AI that creates real value has been running in products for years. On almost every e-commerce project I’ve worked on, the quiet driver of revenue was the recommendation system working in the background, all day, every day.
Legacy AI is a series about those proven systems—what they do, how they’re built, and the trade-offs you face in production. It’s for engineers and product teams who care about results: clear patterns, plain language, and metrics that matter.
We start with e-commerce recommendation engines—the power behind “You may also like.” I’ll cover the signals that matter, how approaches have evolved (from simple “similar items” to modern methods that use vectors and real-time context), and the operational details that protect conversion: caching, cold start, and keeping offline and online behaviour aligned.
In modern e-commerce, recommendation systems aren’t a nice-to-have—they’re core. They turn huge product catalogs into focused, personal discovery for each shopper. The impact is measurable: estimates suggest that for Amazon, up to 35% of purchases come from recommendations. This isn’t just UX polish; it’s a revenue engine that drives retention and lifts average order value.
The technology followed the growth of online retail. Early systems came from information-retrieval research and fought “information overload” with content-based filtering (CBF) and collaborative filtering (CF). As catalogs and user bases grew to massive scale, the limits showed up: data sparsity, cold start, and compute overhead.
That pressure pushed the stack forward. Hybrid approaches combined CBF and CF to balance strengths. Then behavior data exploded—from simple purchases and ratings to every click, view, and session path—alongside richer product data (images, text). Static models couldn’t keep up. Teams adopted deep learning to capture non-linear patterns and sequence effects that classical methods missed.
Today the problem is broader than “filtering.” It’s about understanding users and products end-to-end. Leading retailers run architectures with graph neural networks (GNNs) to model relationships across users and items, and they’re starting to bring in large language models (LLMs) to fuse text, images, and interaction graphs into a single, semantic view.
What this piece covers
The foundational algorithms that still matter today
The deep-learning shift and the neural architectures behind modern systems
Case studies reverse-engineered from public research and technical docs
A review of recommendation capabilities in mainstream e-commerce platforms
The goal is a practical, technical roadmap of the recommendation landscape—from first principles to the current edge.
Section 1: Algorithmic Foundations of E-commerce Recommendation
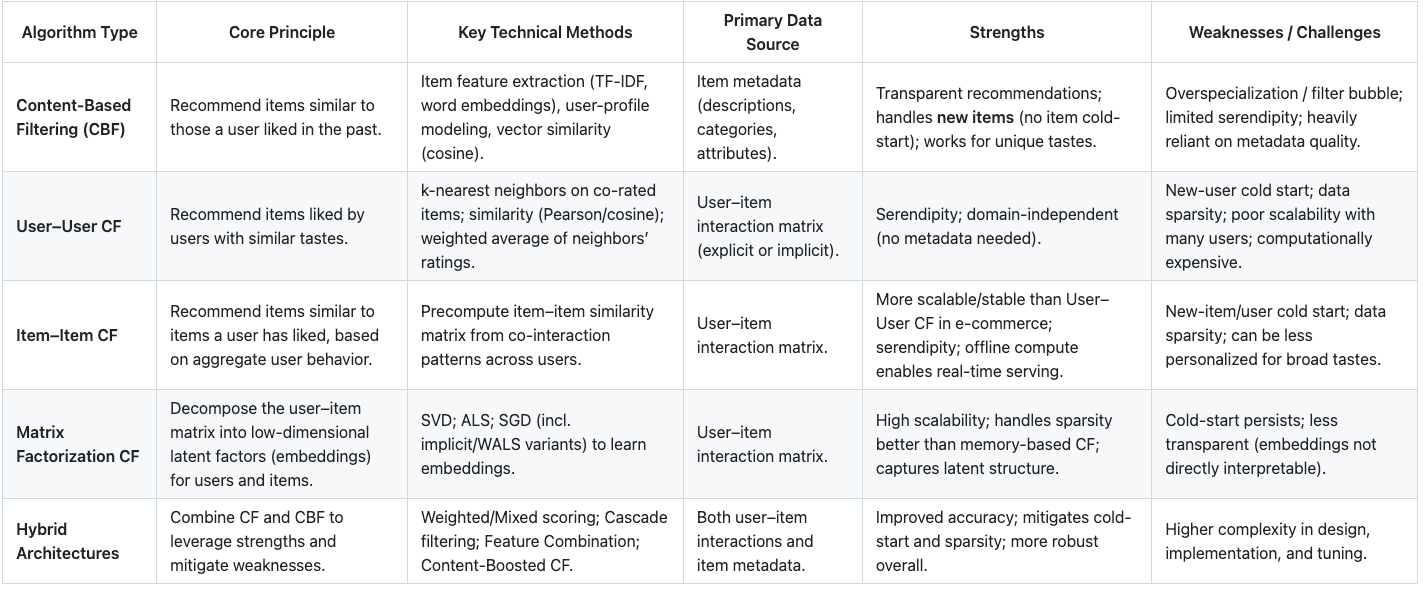
Before deep learning took over, recommenders were built on a few strong ideas: content-based filtering, collaborative filtering, and hybrid setups. These still matter. Knowing how they work—and where they break—helps explain many design choices in modern systems.
1.1 Content-Based Filtering (CBF)
Idea in one line: recommend items with similar properties to the items a user already liked.
How it works
Build item profiles.
Turn each product into a feature vector using its metadata—category, brand, color, material, text description, etc. This step is feature representation/vectorization.
Text features.
TF-IDF: classic approach. It scores each word by how often it appears in a product description and how rare it is across the catalog. You get a high-dimensional, often sparse vector per product.
Embeddings (Word2Vec, GloVe, etc.): modern approach. Words become dense vectors where similar words sit close together (e.g., “smartphone” ~ “mobile phone”). This captures meaning that TF-IDF misses.
Build a user profile.
Aggregate the vectors of items the user liked (purchased, highly rated, long dwell, etc.). Often a weighted average.
Score candidates by similarity.
Compare the user vector to each item vector and rank.
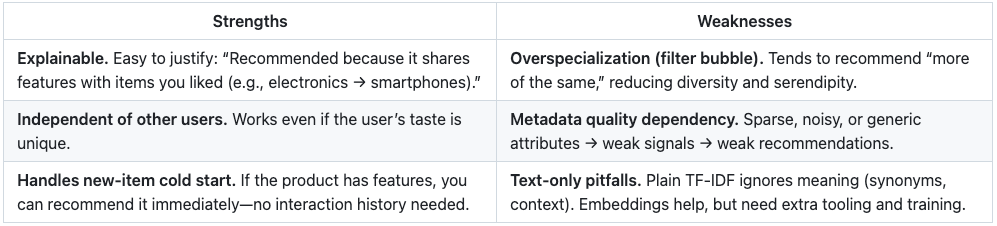
Bottom line: CBF is transparent and fast to ship, great for cold-start on items, and a solid baseline. But without rich features and diversity controls, it narrows user discovery.
1.2 Collaborative Filtering (CF)
What it is.
CF makes recommendations from behavior, not metadata. If users have agreed in the past, they’ll likely agree again. It works with explicit ratings and implicit signals (purchases, clicks, views).
Data shape.
Interactions form a large, sparse user × item matrix. CF’s job is to predict the missing cells (what the user would do with items they haven’t seen).
Memory-based CF (neighborhood methods)
User–User CF.
Find users most similar to the active user (Pearson/cosine over rating vectors). Aggregate neighbors’ ratings to predict a score.
Item–Item CF.
Compute similarities between items based on who interacted with them. Recommend items similar to what the user already liked.
Why this wins at scale: user counts change fast and are huge; item relationships are more stable. You can precompute an item–item matrix offline and serve fast online—this is why item–item became the industrial default.
Model-based CF
Instead of scanning the whole matrix at request time, learn a compact model and use it to score quickly.

1.3 Hybrid Architectures
CBF and CF cover each other’s gaps. Hybrids combine them to keep CF’s accuracy while using content to ease cold-start and sparsity.
Common hybrid patterns
Weighted / Mixed
Run CBF and CF separately, then blend scores (e.g., weighted average). Weights can be dynamic—lean more on CBF for brand-new items.
Cascade
Stage 1 (cheap): use CBF to shortlist a few hundred candidates.
Stage 2 (stronger): use CF to rank the shortlist. Low latency, good quality.
Feature Combination
Feed content attributes (category, brand, text/image features) into a CF model (e.g., augment MF embeddings). Learn from both interactions and item properties.
Content-Boosted CF
Train a content model to fill in missing cells (predict pseudo-ratings) in the sparse user–item matrix, then run standard CF on the densified matrix. Helps with new-item cold start and sparsity.
Bottom line: hybrids give you a sturdier baseline coverage for new items, better quality on known items, and a clean path to scale, setting you up for the multi-signal deep models that follow.
Table 1: Comparison of Foundational Recommendation Algorithms
Section 2: The Deep Learning Revolution in E-commerce Recommendations
The limitations of classical recommendation algorithms, particularly their struggle to capture complex patterns in massive and sparse datasets, paved the way for the deep learning revolution. Neural networks, with their ability to learn hierarchical feature representations and model non-linear relationships, have fundamentally reshaped the architecture of modern recommendation engines. This section details the paradigm shift from traditional models to the sophisticated neural architectures that define the current state-of-the-art, enabling unprecedented levels of personalization and accuracy.
The progression of these deep learning models can be understood as an effort to incorporate increasingly richer and more complex layers of context. Early neural models focused on capturing non-linear interactions. Subsequent architectures evolved to understand sequential context, then relational context, and most recently, the vast semantic and multimodal context embedded within product data.
2.1 Neural Architectures for Collaborative Filtering
The first major advancement was the application of deep neural networks (DNNs) to the collaborative filtering task. This represented a conceptual leap from the linear assumptions of matrix factorization to a more flexible and powerful modelling approach
From Matrix Factorization to Deep Neural Networks
Matrix Factorization (MF) was the first big win in recommenders: learn a vector for each user and item and score them with a dot product. It’s simple, fast, and scales—but it’s linear. Real behaviour isn’t. Users like combinations of signals (“brand × price × use-case”) that a dot product can’t express.
Neural Collaborative Filtering (NCF) fixes this by feeding the concatenated user/item embeddings into a small neural network (an MLP). The network learns non-linear feature crosses and higher-order effects, lifting ranking quality—especially when interactions depend on context.
The Two-Tower Model
While NCF improved modeling power, a more significant architectural innovation for large-scale industrial systems is the two-tower model. This architecture is designed for efficient retrieval in systems with massive item catalogs. It consists of two separate deep neural networks:
User Tower (or Query Tower): This network takes various user features as input (e.g., user ID, demographics, historical interactions) and outputs a final user embedding vector, Uemb.
Item Tower (or Candidate Tower): This network takes item features as input (e.g., item ID, category, brand, text description) and outputs a final item embedding vector, Vemb.
During training, the model learns the parameters of both towers simultaneously. The objective is to maximize the similarity (often calculated using the dot product or cosine similarity) between the output embeddings for positive user-item pairs (i.e., pairs where an interaction occurred) and minimize it for negative pairs.
The primary advantage of the two-tower architecture lies in its serving efficiency. Because the two towers are decoupled until the final similarity calculation, the entire item catalog can be processed through the item tower offline. The resulting item embedding vectors are then indexed into a specialized, high-performance vector search engine, such as FAISS, ScaNN, or a cloud service like Google's Vertex AI Vector Search. At serving time, when a user makes a request, their features are fed through the user tower to generate a user embedding in real-time. This single user vector is then used to perform an Approximate Nearest Neighbor (ANN) search against the millions of pre-computed item vectors in the index. This process can retrieve the top-N most relevant candidates in milliseconds, solving the latency challenge of scoring every item in a massive catalog. This makes the two-tower model the de facto standard for the candidate generation stage in most large-scale industrial recommendation systems
2.2 Capturing User Dynamics: Sequential and Session-Based Models
A critical limitation of traditional CF models, including the basic two-tower architecture, is that they treat user interactions as an unordered set. They capture what a user likes but ignore the crucial context of when and in what order. In e-commerce, the sequence of user actions within a session is a powerful signal of short-term intent. Sequential recommendation models are designed specifically to capture this temporal context.
Recurrent Neural Networks (RNNs)
Early approaches to sequential recommendation employed Recurrent Neural Networks (RNNs), particularly variants like Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU). In this setup, a user's sequence of item interactions is fed into the RNN one item at a time. The RNN maintains a hidden state vector that is updated at each step, effectively creating a summary of the user's evolving interests up to that point. The final hidden state can then be used as a dynamic user embedding to predict the next item they are likely to interact with. LSTMs and GRUs are particularly effective because their gating mechanisms allow them to selectively remember or forget information over long sequences, helping to model both long-term preferences and short-term intent.
Transformers for Recommendation
More recently, the Transformer architecture, originally developed for natural language processing, has proven to be exceptionally powerful for sequential recommendation. Unlike RNNs, which process sequences step-by-step, the Transformer's self-attention mechanism can process all items in a user's history simultaneously. It learns to dynamically weigh the importance of each past item when predicting the next one. For example, if a user is browsing for a new smartphone, the self-attention mechanism can learn to place more weight on their recent views of other smartphones and less on an unrelated purchase of a book from a week ago.
A prime industrial example of this is Alibaba's Behavior Sequence Transformer (BST) model. The BST model takes a sequence of a user's historical behavior (e.g., viewed items) along with other features (user profile, context) as input. The item sequence is fed through a Transformer layer, which uses self-attention to capture the sequential dependencies between the items. The output of the Transformer, which is a rich representation of the user's intent, is then concatenated with other features and passed through an MLP to predict the click-through rate (CTR) for a target item. This architecture demonstrated significant improvements over models that did not explicitly model sequential behavior. This shift from modeling "what a user likes" to "what a user is likely to do next" represents a fundamental evolution in recommendation logic.
2.3 Graph-Based Recommendation Systems
Another powerful way to represent e-commerce data is as a large, heterogeneous graph. In this graph, users and items are nodes, and the interactions between them (e.g., clicks, adds-to-cart, purchases) are edges. This graph structure can capture complex, higher-order relationships that are often missed by other models.
Graph Neural Networks (GNNs)
Graph Neural Networks (GNNs) are a class of neural networks designed to learn directly from graph-structured data. The core operation in a GNN is message passing, where each node iteratively aggregates feature information from its neighbors. After several rounds of message passing, each node's final representation (or embedding) is enriched with information from its local graph neighborhood.
In the context of recommendation, this means that a user's embedding can incorporate information about the items they've interacted with, and an item's embedding can incorporate information about the users who have interacted with it. More powerfully, it captures multi-hop relationships. For example, a GNN can learn that users similar to User A often buy Item B, and Item B is often bought with Item C; therefore, Item C might be a good, albeit non-obvious, recommendation for User A.
Case Study: Alibaba's EGES Model
Alibaba's Enhanced Graph Embedding with Side information (EGES) model is a pioneering industrial application of graph-based methods. The EGES model first constructs a weighted item-item graph from session-based user behavior sequences. The edge weight between two items is based on their co-occurrence in user sessions. The model then uses a graph embedding technique similar to DeepWalk, which performs random walks on the graph to generate node sequences, and then learns item embeddings using the Skip-Gram algorithm.
A key innovation in EGES is how it addresses the cold-start problem. It incorporates item side-information (such as category, brand, and price) into the embedding process. For each item, it learns not only a primary embedding but also embeddings for each of its side-information attributes. The final item embedding is a weighted average of the primary embedding and the attribute embeddings. This allows the model to generate meaningful embeddings even for new or rarely-seen items by leveraging their known attributes, effectively placing them near similar items in the embedding space. This demonstrates how relational context, captured by the graph, provides a powerful framework for understanding product relationships.
2.4 The Generative AI Frontier: LLMs and Multimodality
The most recent and transformative trend in recommendation systems is the application of Generative AI, particularly Large Language Models (LLMs) and multimodal learning. This represents a shift towards models that possess deep semantic understanding and can reason about products and user preferences in a more human-like way.
LLMs as Universal Recommenders
State-of-the-art research is exploring the use of LLMs as general-purpose recommendation engines. Instead of designing specialized models for each task, recommendation can be framed as a natural language problem that an LLM can solve. This can be done in several ways:
Prompting: The LLM is given a prompt containing a user's interaction history and a set of candidate items, and is asked to rank them or predict the next item.
Fine-tuning: An LLM is fine-tuned on a large dataset of user interaction sequences, learning the patterns of e-commerce behavior directly.
Feature Encoding: The LLM is used to generate rich, semantically aware embeddings from textual descriptions of items, which can then be used in downstream models like a two-tower network.
Multimodal Fusion
Modern e-commerce products are not just IDs in a matrix; they are represented by rich, multimodal data including text, images, and structured attributes. The latest systems aim to fuse these different modalities to create a comprehensive understanding of each product.
A leading example is Walmart's Triple Modality Fusion (TMF) framework. This advanced system is designed for multi-behavior recommendations (e.g., predicting views, adds-to-cart, and purchases). It integrates three distinct data modalities:
Visual Data: Product images are processed by a vision encoder (like CLIP) to capture aesthetic and contextual characteristics.
Textual Data: Product titles and descriptions are processed by a text encoder (also CLIP) to capture detailed features and user interests.
Graph Data: A GNN (specifically, MHBT) is used to learn item-behavior embeddings from the heterogeneous interaction graph, capturing relational information.
These three distinct embeddings are then fused into a unified representation using attention mechanisms. The TMF framework employs a modality fusion module based on cross-attention and self-attention to align the different modalities and integrate them into a large language model backbone (Llama2-7B). This allows the LLM to leverage a deep, multifaceted understanding of each product when making recommendations, leading to significant performance gains over models that use only a single data source.
Automated Machine Learning (AutoML) for RecSys
The design of these complex deep learning architectures is a highly specialized and labor-intensive process. Automated Machine Learning (AutoML) has emerged as a field dedicated to automating this process. For recommender systems, AutoML techniques are used to automatically search for optimal configurations for various components, including feature selection, embedding dimensions for different features, the structure of feature interaction layers, and even the overall model architecture. This helps to democratize the development of high-performance models and pushes the boundaries of what is achievable.
Table 2: Deep Learning Architectures for E-commerce Recommendation

Paid add-on: Detailed case studies (Amazon, Alibaba, eBay, Walmart, Etsy), platform capability matrix (Adobe/Shopify/BigCommerce/Woo), and the printable infographic
