
My Vibe coding configuration
What I found useful to build production-ready software with AI (without reading every line)

After few months increasing my “Vibe-coding” activity the question is How do you build production-ready software with AI… and still trust what you’re shipping… without going back to the old habit of reading every line of code?
Because for ~15+ years, my “trust mechanism” was simple:
I read the code. I understood it. I judged it.
But with AI, that approach doesn’t scale. If I’m forced to review everything line-by-line, I burn most of the productivity gains AI promises.
So the real question becomes:
If “reading all the code” is no longer the main tool… what replaces it?
My current answer is: guardrails + automation + disciplined iteration + hoping in the improving model capability.

Tools
Claude Code CLI — Opus 4.5
OpenAI — GPT-5.2
Antigravity IDE — multiple models (I lean on it when I want to exploit the generous free-token offers)
My own “skills + prompts” repo — a personal toolbox I keep improving over time (GitHub)
Ralph Loop — a fork inspired by Matt Pocock (great ideas in there, especially for structuring work)
My step-by-step workflow (same as the last 10 years, just a new audience)
This is exactly how anyway I’ve started projects for the last decade as a Sr. Dev / Tech Lead / Architect:
align the team on expectations
make quality explicit
reduce “interpretation” in delivery
build the right guardrails early
The only difference is that today the audience isn’t only “the team”.
It’s the agents.
1) Start with a CLAUDE.md (scope + architecture decisions)
First, I write a CLAUDE.md that summarizes:
the scope of the product
the non-negotiables
the architectural decisions that form the “foundation layer” of the system
To make those decisions, I usually brainstorm with GPT-5.2 in agent mode, explicitly doing pros/cons and trade-offs.
While writing CLAUDE.md, I often branch into smaller documents (ADR-style),




then link them back into the main CLAUDE.md. The goal is simple:
Help the agent build things in the way I expect — not in whatever way it “feels right”.
2) Make the work “agent-readable”: PRD.json with all user stories
One of the best steals from the Ralph Loop is the PRD.json pattern: a single file that contains the epics + user stories the agent can constantly reference. (GitHub)
In my case, the PRD.json is literally the contract for the agent. For example, it defines the project, the architecture context, and even infra/testing epics as critical prerequisites (before feature work).
It also breaks work down into explicit user stories + subtasks (example: repo setup, branch protection, PR template, etc.).
Before, in personal projects, I was basically “vibing” user stories as I went. In work projects, Jira tickets did the job.
But for agent efficiency, having the full list of user stories available up front is a big upgrade.
3) I focus on infrastructure first (yes, even for “small” projects)
People think CI/CD is overkill for a personal project. I disagree — especially with AI involved.
At minimum, I want:
pre-commit hooks
linting + static checks
automated tests
CI gates that stop bad code from merging
In my PRD, this “infra first” philosophy is literally written as a critical epic (“Must be completed before any feature development begins”), including things like PR templates and branch protection documentation.
With AI, this isn’t optional. It’s fundamental.
The loop: small units of work, same agile idea, stricter gates
I still believe the agile concept holds:
Deliver small increments that are testable.
So for each unit of work, I run a loop:
Read the spec (PRD.json + CLAUDE.md)
Read the guardrails (coding patterns, security rules, team conventions)
Build the code
Verify alignment (PR review vs spec + guardrails)
Test (unit + integration + security + e2e when there’s UI)
Automate the checks in CI/CD
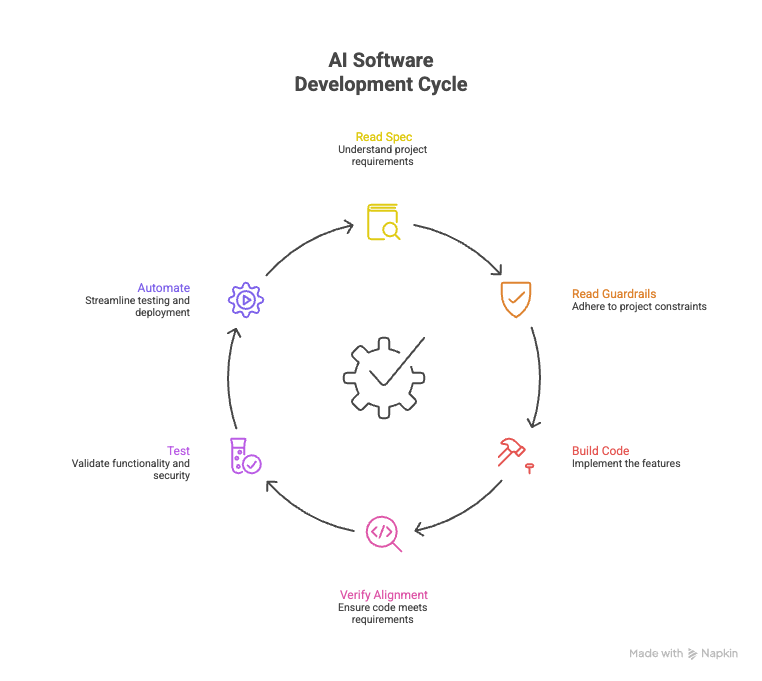
Step 5 is usually a combination of my Claude skills and/or Antigravity agents (often to save paid tokens).
Step 6 is the part I treat as non-negotiable: CI/CD as the trust engine.
Because with AI, I think some form of automated gating is not “nice to have”. It’s foundational.
The guardrails + skills (the part I keep refining)
I keep a repo with prompts/skills that I reuse across projects (PR review templates, security review prompts, etc.). (GitHub)
Even the README is explicit about what it contains (example: a PR review template under prompt/pr-review.md). (GitHub)
This is the “team alignment” equivalent — but for agents.
So… how do I measure trust in practice?
Right now I measure trust with a mix of:
Test coverage + test quality signals (not just % coverage — do tests actually assert meaningful behavior? I often check this manually)
Occasional targeted code review (I still read code, but selectively: risky areas, security boundaries, complex logic)
Running the application and validating each small increment behaves as expected (manual smoke + user-like flows)
And I use PRD.json as the anchor to keep testing honest.
Example: the PRD.json doesn’t just say “write tests”, it specifies the intent and sometimes even the rough scope (e.g., “Write tests for trigger selection” with a stated test count).
That kind of explicitness helps prevent “checkbox testing”.
Why this matters
The hardest shift for me is psychological:
For years, “the code” was the truth.
Now the SDLC has a new abstraction layer.
So we need a different trust strategy — one that still produces secure, performant, maintainable software, but doesn’t require reading everything the model generates.
For me, the best current answer is:
Trust outcome (for this unit)
If:
the story subtasks are demonstrably complete,
tests exist and pass,
CI gates enforce the basics,
and I can run the app and confirm the flow…
…then I don’t need to read every line of code to ship this increment.
I might still spot-check code when the change is security-sensitive or architectural, but the default becomes:
trust the system, not the vibes.
If you’re building with agents too, I’m curious: what’s your trust mechanism?
Do you still read most of the code, or are you also moving toward guardrails + tests + CI gates?
Great breakdown, thank you. Did you notice any "poor quality" code written by the agent?
Like, the code works but looks like my dog wrote it and it's convoluted and inefficient... Or something of that sort...