
Orchestrating the ML Lifecycle: An Engineering Blueprint
Constructing Scalable ML Architectures: A Step-by-Step overview

2023 hit, and there I was, as an architect traditionally dealing with predictable systems, yet I found myself intrigued by the ever-evolving beast that is Machine Learning (ML). Welcoming OpenAI ChatGPT, I started to deepen my knowledge by reading books like "Dive into Deep Learning", using IBM resources about Deploying and managing models and delving into AWS and NVIDIA's documentation, it struck me – ML is a whole different game.
The more I read about advanced deep learning architectures, the more I realized my architecture background wasn’t just ready for this “game”. These resources weren't just informative; they were a wake-up call. ML isn't just about algorithms and data; it's about the interplay of components, challenges, and the tough calls you need to make as an architect.
So here's my angle: How does an ML architecture actually work? What are its moving parts? And most importantly, what are the trade-offs and decisions that keep an ML architect awake at night? This blog post is my dive into these questions, driven by a blend of professional curiosity and a desire to understand the mechanics behind these powerful systems.
The Machine Learning Lifecycle

In the image I've drawn (see Machine Learning Lifecycle diagram), the journey of an ML project begins with a clearly defined problem statement, rooted in a thorough business analysis. This is where we, as architects, lay down the groundwork by translating a business problem into an ML problem. The initial phase is all about understanding the data landscape – pinpointing the required data and dissecting the available raw data – which sets the stage for the feature engineering process.
Feature engineering, a critical and creative phase, involves defining rules that transform raw data into a format palatable for ML models. This process flows into a structured ETL pipeline where data is extracted, transformed, and subsequently loaded, ready for the model development phase.
As we transition to Experimentation, models undergo rigorous training, tuning, and evaluation. This iterative process is a balancing act between model complexity and performance, often influenced by the quality of the engineered features. The feature store system comes into play here, acting as a repository that provides both low and normal latency access to feature sets for real-time inference and batch processing
The Orchestration of these processes is crucial, which is where the scheduler steps in, ensuring that new data triggers model re-training and validation. Embracing MLOps principles, we automate the flow from data extraction to preparation and model training, encapsulating these within CI/CD practices for seamless integration and development.
At the heart of this lifecycle lies the Model Registry, a vault that not only stores model artefacts but also tracks their lineage – a vital component for version control and compliance. It is here that models are prepped for their final destination – deployment into production. This phase includes a staging environment to validate models for security and robustness before they’re served via a robust model serving infrastructure.
The endgame of this lifecycle is a continuous Feedback Loop, a mechanism that doesn't just propel iterative improvement but also guards against model drift in the production environment. Monitoring tools keep a vigilant eye on model performance, ensuring that any deviations are promptly flagged and rectified.
Machine Learning Architecture
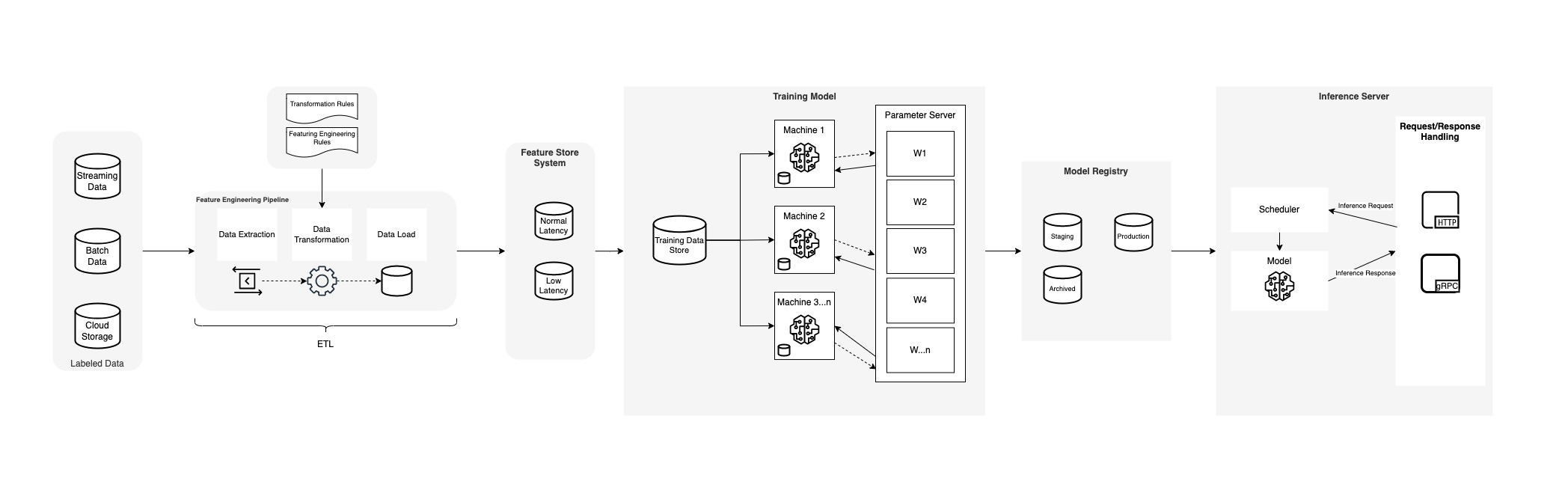
Let’s analyse a typical ML Architecture piece by piece
Data Sources
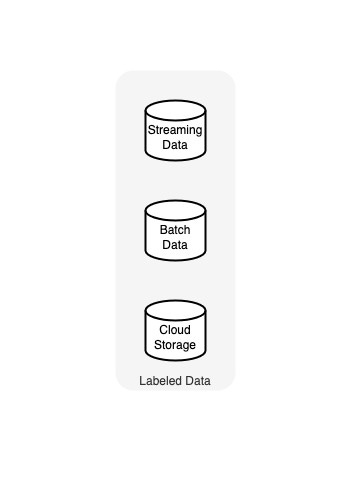
In the 'Data Source' phase of the ML Lifecycle, we're in the domain of data analysis and extraction— a fundamental step where data from streaming inputs, batch processing, and cloud storage converge. The intent here is to lay a solid foundation by amassing a broad spectrum of data that underpins the machine learning models we aim to construct. It's about scouting the landscape for data that can be harnessed to predict outcomes with precision, forming the raw material for the feature engineering to come. Technologies at play include data lakes and warehouses that serve as repositories for this eclectic mix of data, with tools like Apache Hadoop for batch data and cloud services such as AWS S3 for storing vast labeled datasets. Market offerings range from cloud-based platforms that offer integrated data sourcing solutions to open-source frameworks geared towards data ingestion and preliminary analysis. For instance, organizations like financial institutions may tap into this phase by pooling transactional data, customer interactions, and market trends, laying the groundwork for predictive analytics in fraud detection or customer behavior modeling. The challenge lies in sifting through this expanse to identify data that truly informs the ML problem at hand—where relevance is king, and the chaff must be separated from the wheat.
Navigating the 'Data Source' phase comes with its own set of limitations and trade-offs that need astute consideration. When focusing on streaming data, you're faced with the high-stakes balance of capturing real-time insights against the backdrop of potential latency and significant infrastructure investments. On the flip side, batch data processing, while more forgiving on timing, can result in a lag in the freshness of insights, which might be a deal-breaker in fast-paced industries.
Choosing the right cloud storage often becomes a game of balancing cost against scalability and integration with existing systems. Here's the rub: the more comprehensive your data sources, the more complex and resource-intensive the data management becomes. It's about striking that balance between breadth and depth of data without sinking into the quicksand of information overload.
Take the likes of large e-commerce platforms, for instance. They grapple with these trade-offs daily, deciding how to store and process customer data to provide personalized experiences without inflating costs or sacrificing performance. This is the tightrope walk of the data source stage, where every step forward is measured against potential pitfalls lurking just a misstep away
In a production scenario example, consider how Twitter manages its data sources. The platform utilizes streaming data to monitor and analyze billions of tweets in real time, employing technologies like Apache Kafka for swift data ingestion. This allows for immediate trend analysis and user engagement metrics. For historical data analysis, Twitter relies on batch processing, where data is stored in massive data lakes, enabling them to perform complex queries and analyses that inform long-term strategies. These approaches showcase a real-world application where both real-time and batch data are pivotal, and the trade-offs between immediacy and depth of insight are constantly balanced to drive user engagement and business decisions.
Feature Engineering

The Feature Engineering represented above, is where raw data is transformed into a goldmine for machine learning models. This is the stage where transformation and feature engineering rules are meticulously crafted and applied, ensuring that the resulting features are primed for effective model training.
This complex task takes place within the Feature Engineering Pipeline, an orchestrated series of steps encompassing data extraction, transformation, and finally, data loading. Tools like Apache Nifi for data routing and transformation, along with more comprehensive platforms like IBM CP4D, AWS and Databricks, are leveraged for their robust ETL capabilities.
Then there's the Feature Store System – a repository with dual facets. It serves up features with normal latency for batch processing needs, while also catering to the demands of real-time prediction with its low-latency offerings. Tecton and Feast are examples of feature store systems that are gaining traction, providing teams the ability to reuse and share features across models, thereby streamlining the feature engineering process.
However, this phase is not without its challenges. The design and maintenance of feature stores demand a delicate balance between accessibility and performance, ensuring that the right features are available at the right time, without resource wastage. Moreover, the granularity and quality of features can significantly sway model performance, placing a premium on the precision of engineering rules.
In the trenches of production, companies like Uber with its Michelangelo platform, harness feature engineering to fuel their real-time decision engines, ensuring that features like ETA predictions and pricing models are as accurate as they are swift. It's a testament to the critical role feature engineering plays in delivering ML solutions that not only function but excel in real-world applications.
Training Model

The 'Training Model' segment of my ML architecture diagram captures a network of computational nodes—machines dedicated to the arduous task of model training. Each machine, possibly a high-performance GPU or CPU server, runs instances of training algorithms, which iteratively adjust a model's parameters to minimize error against a set of training data. This process demands robust hardware capable of high-speed matrix computations and data processing—a reason why GPUs, with their parallel processing prowess, are often the hardware of choice.
Central to this orchestrated training effort is the Parameter Server, a system designed to synchronize parameter updates across all training nodes. It's the heart of distributed learning, managing the state of the model by aggregating gradients—a technique known as gradient descent—ensuring that each node's updates contribute to a singular, evolving model. This server must be both high-capacity and low-latency to handle the frequent, voluminous exchanges of parameter updates.
This phase leverages software like TensorFlow or PyTorch, frameworks that support distributed model training across multiple hardware nodes, often abstracting the complexities of direct hardware manipulation. They come with built-in support for leveraging Parameter Servers or employing alternative strategies like all-reduce for parameter synchronization.
The technical trade-offs in this stage are significant. More powerful hardware accelerates training but increases costs. The Parameter Server model scales well but can become a bottleneck in extremely large-scale systems, where alternatives like decentralized parameter updating might be considered.
In live production environments, tech companies might deploy these training models on cloud platforms like AWS or Azure, which provide scalable GPU resources on-demand. For example, an autonomous vehicle company might use such a setup to train driving models on petabytes of sensor data, requiring immense computational resources and sophisticated parameter synchronization to simulate and learn from countless driving scenarios.
In production environments, companies often require substantial computational power to train complex ML models. For example, a financial analytics firm might use distributed clusters of machines, each equipped with GPUs for parallel processing, to train models on market data and predict stock trends. They could leverage a setup involving Kubernetes to orchestrate containerized machine learning workloads across a cloud environment, optimizing resource use and scaling training operations on demand.
For parameter synchronization, they might implement an elastic Parameter Server framework or utilize decentralized strategies like ring-allreduce, which can offer better scalability and fault tolerance. Such choices depend on the size of the model, the frequency of parameter updates, and the overall network topology.
Additionally, leading cloud providers offer Machine Learning as a Service (MLaaS) platforms, which abstract away much of the underlying infrastructure complexity. These platforms provide integrated tools for model training, parameter tuning, version control, and deployment, streamlining the entire lifecycle of ML model development.
In the context of real-world applications, consider a healthcare organization using MLaaS to train models for predicting patient outcomes. They would utilize the vast computational resources offered by cloud services, paired with sophisticated model management systems, to ensure that their predictive models are as accurate and up-to-date as possible, ultimately aiming to provide better care and save lives.
A well-known example in the context of financial analytics could be JPMorgan Chase & Co. They have leveraged distributed computing for risk modeling and fraud detection. Their platform, Athena, is known for processing vast amounts of financial data, and for such data-intensive tasks, they use scalable cloud computing resources that can handle the computational load.
In healthcare, Philips is known for its HealthSuite platform, which uses advanced analytics to improve patient care. They train complex models on large datasets of patient information, using scalable cloud infrastructure to manage and process this sensitive data securely and efficiently. Philips' use of MLaaS enables them to continuously refine their predictive models, which can lead to more personalized patient care plans and better health outcomes.
Inference Server
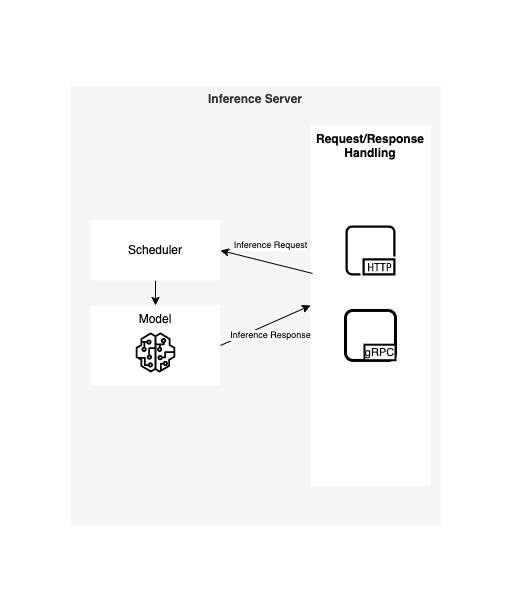
The 'Inference Server' segment of the ML architecture diagram depicts the critical role of inference servers in deploying and managing machine learning models for real-world applications. These servers act as intermediaries between client applications and trained machine learning models, handling the complex task of interpreting user requests and executing the appropriate model computations to generate meaningful inferences.
The diagram highlights the interplay between the Inference Server, the Model, and the Client Application. The Client Application submits an Inference Request, which is typically a data payload containing the input features for the target machine learning model. This request is then routed to the Inference Server, which acts as a centralized repository for managing multiple machine learning models.
Software: The client application can be written in any programming language that supports HTTP communication. Popular options include Python, Java, and JavaScript.
Hardware: The client application can run on a variety of devices, including desktops, laptops, mobile phones, and servers. The specific hardware requirements will depend on the complexity of the inference request and the desired performance.
Within the Inference Server, the Scheduler component receives the incoming Inference Request and determines which Model is the most appropriate for handling the request based on the type of input data and the specific task at hand. The selected Model is then activated and loaded into memory, ready to process the input data.
Software: The inference server typically runs on a dedicated server machine. The server should have a powerful CPU or GPU to handle the computational demands of the machine learning models. Common inference server software frameworks include TensorFlow Serving, PyTorch Serving, and Apache MXNet.
Hardware: The inference server hardware will depend on the specific inference requirements. For basic inference tasks, a standard server with a CPU or a low-end GPU may be sufficient. For more demanding tasks, a high-end GPU server may be necessary.
Once the Model is loaded, the Request/Response Handling mechanism takes over, orchestrating the communication between the Model and the Client Application. The Inference Server communicates with the Model using the HTTP protocol, sending the input data and receiving the Inference Response, which contains the generated predictions or insights from the model.
Software: The model is the trained machine learning model that is deployed on the inference server. The model can be represented in a variety of formats, such as TensorFlow SavedModel, Keras HDF5, or ONNX.
Hardware: The model hardware requirements will depend on the size and complexity of the model. For smaller models, a standard server may be sufficient. For larger models, a dedicated hardware accelerator may be necessary.
Scheduler
Software: The scheduler is responsible for managing the execution of inference requests. It receives incoming requests, determines which model to use, and loads the model into memory. Popular scheduler software frameworks include TensorFlow Serving, Model Serving, and Apache Flink.
Hardware: The scheduler can run on the same server as the inference server or on a separate server. The hardware requirements will depend on the number of concurrent inference requests.
Request/Response Handling
Software: The request/response handling mechanism is responsible for communicating between the inference server and the client application. It sends the input data to the model, receives the inference result, and sends the result back to the client application. Popular request/response handling libraries include HTTP, gRPC, and Apache Kafka.
Hardware: The request/response handling mechanism can run on the same server as the scheduler or on a separate server. The hardware requirements will depend on the number of concurrent inference requests and the network bandwidth.
This process encapsulates the fundamental role of inference servers in translating user requests into meaningful inferences through machine learning models. They act as the bridge between the application layer and the underlying machine learning expertise, enabling the seamless integration of AI into various domains.
Conclusion
As you can see, machine learning architecture is a complex and ever-evolving field. There are many different components that need to be considered, and the trade-offs between them can be significant. However, by understanding the different phases of the ML lifecycle and the role of each component, we can make informed decisions about how to architect your machine learning solutions.
Here are some key takeaways from this blog post:
The ML lifecycle is a series of steps that begins with problem definition and ends with deployment and monitoring.
Each phase of the ML lifecycle has its own set of challenges and trade-offs.
Machine learning architecture is about choosing the right tools and frameworks to support the ML lifecycle.
The specific architecture you choose will depend on your specific needs and constraints.
I hope this blog post has given you a better understanding of machine learning architecture. If you have any questions, please feel free to leave a comment below.