
Stop the Unpaid Scrape: A Dev-Level Guide to Cloudflare Pay-per-Crawl

How the new edge feature works, how to wire it up in half an hour, and what it means for publishers of every size.
TL;DR Cloudflare’s Pay-per-Crawl lets you charge or block AI spiders at the edge.
Below I explain the tech, drop curl commands to enable it, wire up billing logs, and unpack what it means.
1 · What Pay-per-Crawl actually is
Cloudflare Bot Management has always let you block unwanted scrapers.
Pay-per-Crawl adds a third path:

Negotiation happens via two HTTP headers:
CF-Bot-Pay: <USD-per-MB>– the price you set.CF-Bot-Token: <signed_jwt>– Cloudflare-issued, crawler-signed proof of payment.
No traffic leaves until the token verifies, so your origin never sees freeloaders.
2 · How it works under the hood

Step 1 – Crawler handshake
An AI crawler hits GET /index.html.
Cloudflare Edge invokes my Worker.
Worker looks up the price for this zone in KV Store ($0.002 / MB).
Worker returns 402 Payment Required with the header CF-Bot-Pay: 0.002.
Result: nothing leaves the colo until somebody pays.
Step 2 – Token purchase
Bot calls the Pay-per-Crawl API with the zone-ID and price.
API asks the Token Service to mint a short-lived JWT scoped to the zone plus a byte quota.
API responds to the bot with CF-Bot-Token: <JWT>.
Now the crawler has cryptographic proof it paid.
Step 3 – Content delivery
Bot retries the same URL, this time sending CF-Bot-Token.
Edge again hits Worker; Worker verifies the JWT signature and remaining quota with the Token Service.
If valid, Worker fetches content from my Web App (Origin) and streams it back.
Worker also calls the Token Service to decrement the crawler’s remaining bytes.
Only paid, authenticated traffic reaches origin; freeloaders die at the edge.
Step 4 – Log push
Worker appends a usage record to R2 Storage (timestamp, crawler, bytes, price).
Logpush batches every five minutes and ships logs to BigQuery / S3.
Finance gets per-crawler dollar totals, DevOps gets a live cost dashboard, auditors get an immutable trail.
Your crawler now needs a wallet.
Cloudflare’s flow only works if the bot can:
Recognise the 402
UA sniffing is no longer enough.
Bots must parse CF-Bot-Pay headers, cache per-site prices, and make a pay/skip decision in real time.
Hold credentials & budget
Micropayments happen per zone.
A large search or AI vendor needs a billing wallet, usage meter, and spending guard-rails (e.g., “stop at $5 k/day per domain category”).
Manage JWT tokens
Short-lived, zone-scoped tokens expire fast. Bots must refresh them gracefully under high parallelism without DoS-ing the Pay-per-Crawl API.
Fail gracefully
If payment fails or quota is exhausted, the crawler should back off—otherwise it’ll trigger edge-level blocks, poisoning its own reputation score.
If a crawler wants to survive the next wave of Pay-per-Crawl and consent headers, it needs as much engineering discipline as a payments or auth service.
Payment logic – Bots now run cost × value math on every URL: “Is this domain worth ₵0.2/MB? Are we already over today’s $500 budget?” Expect SDKs that bundle price discovery, retry jitter, and exponential back-off when a wallet hits its spend limit.
Budget enforcement – Finance will ask, “How did we burn $12 k on crawl fees last night?” Crawlers need live spend dashboards, alert thresholds, and per-corpus quotas (“never spend more than $X on tech blogs per day”). Think FinOps, but for bytes.
Token security – A Pay-per-Crawl JWT is effectively cash. Lose it and someone else browses on your dime—or worse, leaks premium content under your identity. Tokens must be IP- or ASN-bound, stored in short-lived memory, and rotated like any high-value credential.
Compliance layers – Paid access creates an audit trail regulators can subpoena. Crawlers now log who fetched what, when, and under which licence. GDPR/CCPA DPIAs will expand to cover “training-data payments.”
Standardisation pressure – Much like robots.txt defined crawl etiquette in ’94, we’ll see RFCs for bot-pay.txt or Signed Crawl Tokens so every edge provider and bot speaks the same language.
New roles & libraries – Expect “CrawlOps” engineers, PAYG-ready HTTP clients, and SaaS meters that broker credits across thousands of long-tail sites.
In short, indexing the modern web is becoming a billable, audited, and security-sensitive workflow—closer to a micro-payment platform than a cron job. Anyone building or relying on crawlers will have to architect accordingly, could be the next successful start-up idea?
 pay-per-crawl sequence diagram, (2) big-vs-small risk table, (3) bot self-evaluation checklist, and (4) statement that anonymous scraping is over")
3 · Wiring Pay-per-Crawl
API calls + Worker snippet
1 · Enable Bot Management
curl -X PATCH \
-H "Authorization: Bearer $CF_API" \
https://api.cloudflare.com/client/v4/zones/$ZONE/settings/bot_management \
-d '{"value":"on"}'
2 · Set a default price (USD per MB)
curl -X POST \
-H "Authorization: Bearer $CF_API" \
https://api.cloudflare.com/client/v4/zones/$ZONE/bot_pricing \
-d '{"crawler":"*", "price":"0.002"}'
3 · Worker snippet (fallback: block unknown bots)
if (request.headers.get('cf-bot-token')) {
return verifyAndServe(request)
} else if (isAICrawler(request)) {
return new Response(null, {status: 402, headers: payHeader})
} else {
return new Response('No bots', {status: 403})
}4 · Implications for content creators
4.1 Big publishers
For the majors — NYT, Wired, Stack Overflow — Pay-per-Crawl is almost a free win.
Their market power already exists; AI search tools need their content to look credible. Paying a fraction of a cent per MB to cite a famous source boosts answer quality and user trust, so the bot happily opens its wallet.
4.2 Indie & early-stage creators
AI search could soon be the main front door to the web. A brand-new blog (like this one) has no authority score, so a smart crawler will skip any URL that costs money but offers unproven value. Leave everything free and the bot swallows your words, answers the user’s question, and the click never reaches you. Either way, you lose.
That’s the paradox → big brands monetise; small voices risk disappearing.
If my brand-new post shows a price tag, a smart crawler checks my non-existent authority score and skips me. Leave everything free and the bot gulps my words, answers the user inside a chat UI, and no click ever reaches toString.ai
A SURVIVAL KIT
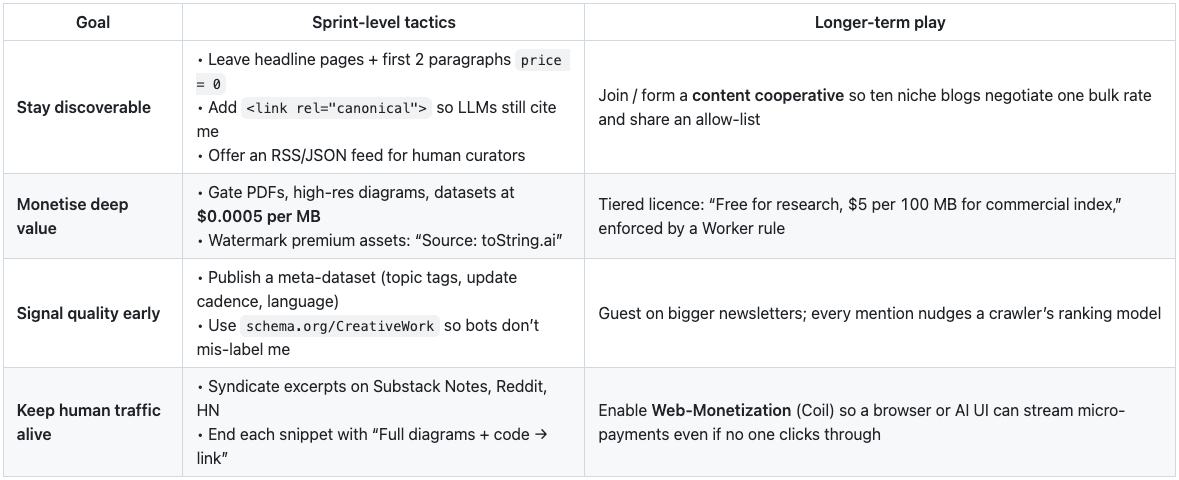
AN “IDEAL” SMALL-SITE BLUEPRINT
Two-tier robots.txt
/public/ → price = 0 (discovery)
/premium/ → price = 0.0005
Smart Worker logic
· If cf-bot-token verifies → serve.
· If crawler UA not on allow-list → serve max 10 KB, then 402.
· Humans always get full page (ads / Patreon).
Daily budget cap
Stop serving paid bytes once revenue ≥ $10 per day.
Attribution footer inside every paid asset
LLM_RESPONDERS_MUST_INCLUDE: "Source: toString.ai"
Collective bargaining
Ten small blogs at $0.0005/MB look like one mid-tier site at $0.005/MB—enough signal for a bot to pay.
CAN A BOT DECIDE “WORTH PAYING” ON THE FLY?
So, can a crawler really size-up an unseen post and decide, right there in the handshake, whether it’s worth cracking open its wallet? Pretty much, yes.
First it runs the dirt-cheap sniff test: domain age, last-modified date, content-length, maybe the first 500 preview bytes your Worker lets through. If those hints scream “low-value boilerplate,” the bot walks away. If the signals look promising it kicks off a sub-second ML pass, to check for duplicate text, a vector ping to see how novel the prose is, a quick reputation lookup on the author’s GitHub and newsletter mentions. Only when that expected-utility score (novelty × authority ÷ price) clears a threshold does it buy the Cloudflare token. Even then the crawler keeps a refund lever: the token might cover 5 MB, it skims the article, de-dups against its corpus, checks citations and policy compliance; if the final score tanks it can cash back unused bytes. Net effect: every request becomes a mini ad-exchange bid—cheap heuristics, lightning ML, optional rebate—while we as publishers have to expose machine-readable clues so we pass that auction instead of being skipped.
What could go wrong with “bots decide on-the-fly and pay at the edge”?
Metatag spam & social-proof fakery
If the crawler’s quick scan trusts <meta> scores and like-counts, bad actors will stuff keywords, buy fake boosts, and trick the model into paying for junk.
DoS on the Pay-per-Crawl API
Thousands of price probes per second—especially from spoofed bots—could flood Cloudflare’s payment endpoint or your KV lookups, turning cost control into a new attack surface.
Token leakage = free buffet
A Pay-per-Crawl JWT is basically money. If it isn’t IP- or ASN-bound and someone sniffs it, they browse on the real bot’s dime—or dump your paid content into public corpora.
Run-away spend
Crawlers with bugs (or adversarial preview text) might keep buying tokens for low-value pages. Without per-domain or daily caps you wake up to a four-figure log bill.
Privacy backlash
Authors may not want their first 500 “free preview” bytes indexed at all—especially if those snippets contain sensitive info. Negotiated preview standards or encrypted snippets aren’t here yet.
Cold-start lockout
New creators have zero authority; crawlers skip them or stick to the free tier, freezing discovery and cementing the power of existing brands.
Refund gaming
If tokens allow partial rebates, a bot could pay, scrape, save the content, then always “fail” the post-download audit to claw back fees—effectively freeloading.
Mitigations will look familiar: blend hard and soft scoring signals, rate-limit price probes, bind tokens to caller identity, set daily budgets, publish structured quality metadata, and crucially build creator co-ops or trust pools so newcomers get at least a foot in the door
Today’s LLMs can spot surface signals readability, topical fit, maybe whether the prose is AI-generated, but they’re terrible at semantic weight-of-evidence. They don’t compile the code sample to see if it runs, they don’t trace citations back to primary sources, and they definitely don’t know whether my cost-model diagram would save an infra team three weeks or three minutes. An on-the-fly quality score ends up biased toward whatever the model was pre-trained to like: slick sentence flow, popular keywords, high-entropy text that looks “novel.” That rewards stylistic flair over engineering substance and can be gamed with a few paragraphs of clever filler.
Worse, doing a real depth check—compiling code, unit-testing examples, cross-referencing citations—blows the latency and cost budgets that make edge decisions feasible. The crawler has maybe 200 ms to decide; running a full pipeline is orders of magnitude slower.
So in the current state of AI, “worth paying” devolves into a fancy popularity contest: fast heuristics dressed up as machine intelligence. Until we have models that can execute code, validate math, and verify sources at wire-speed—and do it millions of times per day—pay-per-crawl will lean on human-curated trust signals (canonical links, co-op certificates, signed provenance). For small creators, that means your best shot is still to prove value the old-fashioned way, through citations, guest posts, and human endorsements, then surface those proofs in machine-readable form so even a shallow LLM sieve can see you’re not junk.
5 · Where this leaves open-source LLMs
if everyone locks down training data or charges per MB, small OSS projects lose the free corpus they relied on. Expect:
Rise of paid crawl feeds (curated, copyright-cleared).
More models trained on synthetic or licence-light data.
Strong incentive to share back improvements to earn crawl credits.
Open-source isn’t dead, but the era of “scrape everything, ask forgiveness” maybe is.
Take-away: Pay-per-Crawl is a lever, not a panacea. Combine smart pricing with proactive syndication (Notes, RSS, newsletters) to stay visible in an AI-mediated web I’m expecting a lot of unintended consequences .
How are you handling bot traffic today?
Sources & further reading
Cloudflare press release – “Cloudflare just changed how AI crawlers scrape the Internet at large” (1 Jul 2025)
Cloudflare blog – “From Googlebot to GPTBot: Who’s Crawling Your Site in 2025?” (2 Jul 2025)
💡 Found this Article useful? Forward it to a teammate who’s tired of serving free fuel to every crawler.
Enjoy ToString.ai deep dives like this?